DeepSeek R1本地化部署:再也不用担心DS服务器繁忙了

本文作者简介:
李锡涵(Xihan Li),伦敦大学学院(UCL)计算机系的博士研究生,同时也是一位谷歌开发者专家。他的主要研究方向是学习优化,并在 NeurIPS、ICLR、AAMAS 和 CIKM 等顶级学术会议上发表过多篇论文。此外,他还是 Circuit Transformer 的作者,以及图书《简明的 TensorFlow 2》(https://tf.wiki)的作者。
DeepSeek 的爆火现象
今年春节期间,AI工具 DeepSeek 可以说是彻底“破圈”了,从专业圈火到大众圈,几乎成了家喻户晓的工具。无论是网页版还是 APP 版,DeepSeek 的功能已经非常强大且易用,但如果你想要更高的自由度和个性化体验,把模型部署到本地才是更好的选择。这样一来,DeepSeek R1 的强大功能就能真正为你量身定制,实现“以你为主,为你所用”。
关于本地部署的一些问题
目前,大多数用户在本地部署时,使用的都是经过蒸馏的 8B、32B 或 70B 版本。这些模型本质上是基于 Llama 或 Qwen 的微调版本,虽然性能不错,但并不能完全发挥出 DeepSeek R1 的全部潜力。如果你追求更高性能,可能还需要探索更原生的模型方案。
如何在本地运行超大模型?DeepSeek R1 671B 的简明教程
想象一下,一个体积高达 720GB 的超大模型可以被压缩到普通消费者的设备上运行,比如一台 Mac Studio。这听起来是不是有点不可思议?但通过一些巧妙的技术手段,比如“量化技术”,这个梦想已经成为现实。今天,我们就来聊聊如何使用 ollama 在本地部署完整的 DeepSeek R1 671B 模型(未经过蒸馏的原版),并且这篇教程已经在海外引发了广泛关注。
- 作者主页:Snowkylin
- 原文地址:DeepSeek R1 部署教程
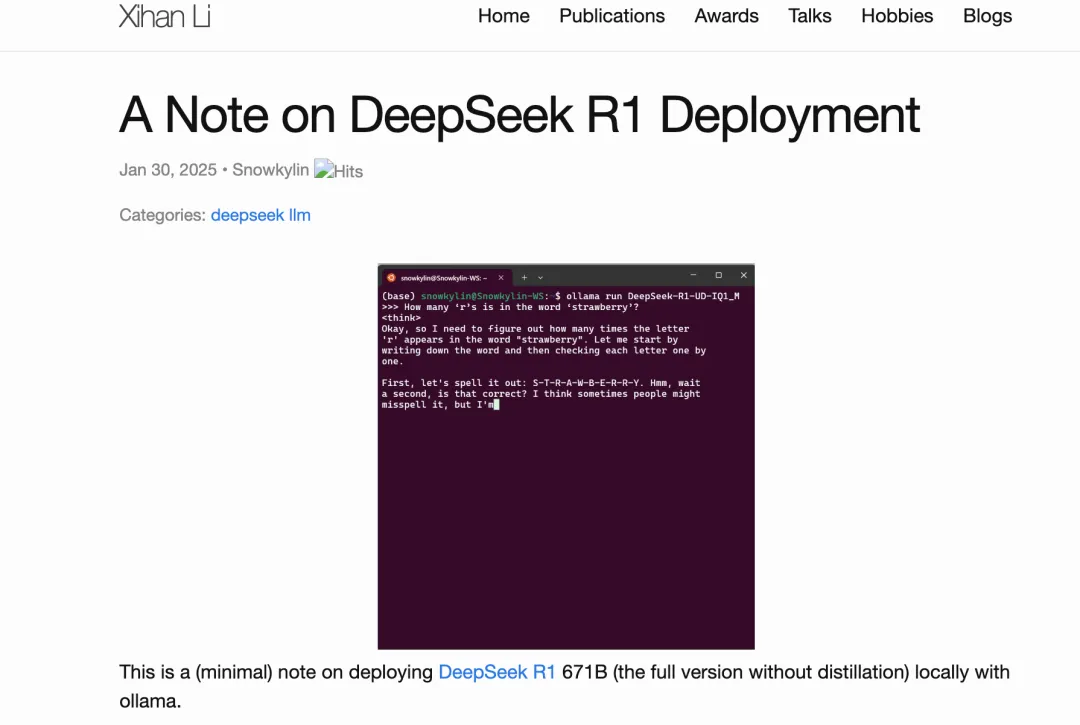
本地部署后,让 DeepSeek R1 来“数草莓”
模型体积太大?动态量化来帮忙!
DeepSeek R1 的原版模型(全量 671B 参数)文件体积高达 720GB,这对绝大多数用户来说简直是“天文数字”,普通电脑根本无法承受。为了解决这个问题,本文推荐使用 Unsloth AI 在 HuggingFace 平台上提供的“动态量化”版本。这种量化技术可以大幅压缩模型体积,让它变得更加“轻量化”,从而让普通用户也能在自己的设备上运行这个超大模型。
通过这种方法,原本高高在上的 DeepSeek R1 模型也能“飞入寻常百姓家”,甚至可以在消费级硬件上轻松部署。是不是很让人心动?
接下来,我们将继续探索如何具体操作,把这个庞然大物装进你的电脑里!
什么是“动态量化”?一文带你轻松了解
“动态量化”听起来很高深,但其实它的核心思路并不复杂。简单来说,就是对模型的不同部分进行“精准压缩”。具体做法是:
- 关键部分:对模型中非常重要的层,采用高质量的4到6比特量化,保证性能不受太大影响。
- 非关键部分:对那些相对不那么重要的部分,比如混合专家层(MoE),进行大胆的1到2比特量化,大幅减少模型占用的存储空间。
通过这种“按需分配”的方式,DeepSeek R1 模型被压缩得非常小,最小版本仅需 131GB(相当于平均1.58比特量化)。这意味着,即使是普通的设备,比如一台 Mac Studio,也能运行这个模型了!是不是很神奇?
我的测试:两款模型对比
为了验证效果,我在自己的工作站上测试了以下两款模型:
- DeepSeek-R1-UD-IQ1_M
- 参数量:671B
- 平均量化:1.73比特
- 文件大小:158GB
- 来源:HuggingFace
- DeepSeek-R1-Q4_K_M
- 参数量:671B
- 平均量化:4比特(标准量化)
- 文件大小:404GB
- 来源:HuggingFace
从文件大小上可以看出,动态量化版本(1.73比特)要比标准量化版本(4比特)小得多,这对硬件资源有限的用户来说非常友好。
Unsloth AI 提供的动态量化模型
如果你也想试试,Unsloth AI 提供了 4种动态量化模型,量化范围从 1.58比特到2.51比特,文件大小从 131GB到212GB 不等。你可以根据自己的硬件条件选择合适的版本。具体差异可以参考官方说明:
Unsloth AI 官方说明
部署硬件需求
当然,运行这样的大模型对硬件还是有一定要求的,尤其是内存和显存。以下是官方推荐的配置:
- DeepSeek-R1-UD-IQ1_M:内存 + 显存总和 ≥ 200GB
如果你的设备达不到这个要求,可以选择更小的版本,或者考虑云端部署。
总之,动态量化技术让大模型的本地部署变得更加轻松。如果你对 AI 技术感兴趣,不妨试试看,或许会有意想不到的惊喜!
深入浅出:DeepSeek-R1-Q4_K_M 模型运行指南
如果你对人工智能模型的运行环境感兴趣,尤其是像 DeepSeek-R1-Q4_K_M 这样的高性能模型,那么这篇文章将帮你更轻松地了解它的运行需求和性能表现。
运行环境需求:内存 + 显存 ≥ 500GB
要运行 DeepSeek-R1-Q4_K_M 模型,系统的内存和显存总和需要达到至少 500GB。这是因为我们使用了 ollama 工具来部署模型。
Ollama 的优势在于它支持 CPU 和 GPU 的混合推理,也就是说,部分模型层可以加载到显存中以加速运行。因此,内存和显存的总和可以被看作系统的“总内存空间”。
为什么需要这么多内存?
模型本身会占用大量的内存和显存。以 DeepSeek-R1-Q4_K_M 为例:
- 模型参数需要 158GB 的内存和404GB 的显存。
- 运行时还需要额外的空间来存储上下文缓存。简单来说,上下文缓存是模型用来记住生成内容的“记忆空间”。预留的空间越多,模型能够处理的上下文窗口就越大,也就是它能记住更多的对话内容。
测试环境配置
为了让模型顺畅运行,我们使用了以下硬件配置:
- 显卡:4 张 RTX 4090(每张显存为 24GB,总显存 96GB)
- 内存:4 条 DDR5 5600 内存条(每条 96GB,总内存 384GB)
- CPU:AMD ThreadRipper 7980X(64 核)
这种配置可以说是非常高端,适合需要运行大规模 AI 模型的场景。
运行速度表现
在上述配置下,模型的运行速度表现如下:
-
短文本生成(约 500 个 token)
- DeepSeek-R1-UD-IQ1_M:每秒生成 7-8 个 token(如果只用 CPU 推理,则为 4-5 个 token/秒)。
- DeepSeek-R1-Q4_K_M:每秒生成 2-4 个 token。
-
长文本生成
- 当生成更长的文本时,速度会下降到每秒 1-2 个 token。这是因为需要处理的上下文窗口更大,对内存和显存的需求也更高。
总结
运行 DeepSeek-R1-Q4_K_M 模型需要一个强大的硬件环境,尤其是大容量的内存和显存。Ollama 的混合推理功能让 CPU 和 GPU 能够协同工作,提升了运行效率。在高端配置下,这些模型可以实现较快的生成速度,但处理长文本时仍会受到硬件性能的限制。
如果你正在考虑部署类似的模型,记得根据你的具体需求选择合适的硬件配置,并预留足够的内存和显存空间以确保运行流畅!
如果你对大模型推理感兴趣,但预算有限,那么选择合适的硬件配置是非常重要的。虽然我之前的测试环境并不是性价比最高的方案(主要是为了我的 Circuit Transformer 研究,感兴趣的朋友可以查阅 [arXiv:2403.13838],该研究刚刚被 ICLR 会议接收),但这次我整理了一些更具性价比的硬件选择,供大家参考。
更具性价比的硬件选项
以下是一些适合大模型推理的硬件配置,性价比相对较高:
-
Mac Studio
- 配备大容量且高带宽的统一内存。
- 示例:X 平台上的 @awnihannun 使用了两台 192GB 内存的 Mac Studio 来运行 3-bit 量化版本的大模型。
-
高内存带宽的服务器
- 示例:HuggingFace 的用户 alain401 使用了一台配备 24×16GB DDR5 4800 内存的服务器。
-
云 GPU 服务器
- 配置:2 张或更多 80GB 显存的 GPU(如英伟达 H100)。
- 成本:租赁价格大约为 2 美元/小时/卡。
硬件资源不足怎么办?
如果你的硬件条件有限,可以尝试运行体积更小的 1.58-bit 量化版(需要约 131GB 内存)。以下是一些可行的硬件方案:
-
单台 Mac Studio
- 配置:192GB 统一内存。
- 示例:X 平台上的 @ggerganov 成功运行了该版本,硬件成本约为 5600 美元。
-
2×Nvidia H100 80GB GPU
- 示例:X 平台上的 @hokazuya 使用了这一配置,运行成本约为 4~5 美元/小时。
性能表现
在上述硬件配置下,运行速度可以达到 每秒生成 10 个以上的 token,对于大模型推理来说已经相当不错了。
无论是选择本地硬件还是云端服务,都可以根据自己的预算和需求灵活调整。如果你对大模型推理有兴趣,不妨试试这些配置,找到最适合自己的解决方案!
如何在Linux环境下部署模型:通俗版教程
如果你用的是Linux系统,这里有一份简单易懂的指南,教你如何部署模型。如果你用的是Mac OS或Windows,操作大体类似,但有些工具的安装方式和默认文件位置可能会稍有不同,比如 ollama 和 llama.cpp 的版本选择。以下是具体步骤:
1. 下载模型文件
首先,你需要从 HuggingFace 网站下载模型文件。模型地址是:HuggingFace DeepSeek-R1-GGUF。
注意: 这个文件体积很大,建议用专业的下载工具,比如 XDM(我用的就是这个)。下载完成后,如果文件是分片的,记得把它们合并成一个完整文件(参考注释 1)。
2. 安装 ollama
ollama 是一个工具,用于加载和运行模型。你可以从 ollama官网 下载它。
安装非常简单,只需打开终端,执行以下命令即可:
curl -fsSL https://ollama.com/install.sh | sh3. 创建 Modelfile 文件
接下来,你需要创建一个名为 Modelfile 的文件,这个文件用来告诉 ollama 如何加载模型。
你可以用任何喜欢的文本编辑器来创建这个文件,比如 nano 或 vim。
以下是一个示例文件的内容,假设你正在使用 DeepSeek-R1 模型(文件名为 DeepSeekQ1_Modelfile,对应模型 DeepSeek-R1-UD-IQ1_M):
继续按照后续步骤操作即可!
这段内容主要是在讲解如何配置和创建一个 AI 模型的运行环境,但表述较为技术化。下面我将其改写为更通俗易懂的版本,方便更多读者理解。
配置模型文件路径和参数
在配置模型时,你需要对文件路径和参数进行调整。以下是一个示例:
FROM /home/snowkylin/DeepSeek-R1-UD-IQ1_M.ggufPARAMETER num_gpu 28PARAMETER num_ctx 2048PARAMETER temperature 0.6TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"如果你使用的是 DeepSeekQ4 模型文件(对应于 DeepSeek-R1-Q4_K_M),它的内容可能是这样的:
FROM /home/snowkylin/DeepSeek-R1-Q4_K_M.ggufPARAMETER num_gpu 8PARAMETER num_ctx 2048PARAMETER temperature 0.6TEMPLATE "<|User|>{{ .Prompt }}<|Assistant|>"注意:
在这里,你需要将 FROM 后面的文件路径改为你在第1步中下载并合并的 .gguf 文件的实际路径。
此外,根据你的硬件配置,可以调整以下参数:
- num_gpu:表示用于加载模型的 GPU 数量。
- num_ctx:表示上下文窗口的大小,影响模型处理的文本长度。
具体参数调整方法可以参考步骤 6 的说明。
创建 Ollama 模型
完成模型描述文件的配置后,进入该文件所在的目录,运行以下命令即可创建模型:
通过这种方式,用户可以根据自己的需求和硬件条件灵活调整模型配置,更高效地完成 AI 模型的部署和运行。
如何简单上手运行 DeepSeek 模型?
如果你是第一次接触 DeepSeek 模型,可能会觉得操作有些复杂。别担心,我来用更简单的方式为你解读这段内容,让你轻松上手!
1. 创建模型文件
首先,你需要通过以下命令创建一个 DeepSeek 模型实例:
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile这个命令会根据指定的模型文件(DeepSeekQ1_Modelfile)在你的系统中生成一系列模型文件。这些文件会被存放在 Ollama 的模型目录中,默认路径是:
/usr/share/ollama/.ollama/models注意:
确保这个目录有足够的存储空间,因为生成的模型文件大小会和你下载的 .gguf 文件差不多。如果空间不足,可以通过修改 Ollama 的配置文件来更改模型存储路径(具体方法请参考官方文档)。
2. 运行模型
当模型文件创建完成后,你可以通过以下命令运行它:
ollama run DeepSeek-R1-UD-IQ1_M --verbose这里的参数:
--verbose:这个选项会让程序显示运行时的详细信息,比如每秒处理的 token 数量(也就是推理速度)。
3. 遇到问题怎么办?
如果运行过程中出现了内存不足或CUDA 错误,别慌!这是因为模型的大小超过了你的显卡或系统内存的承受范围。解决方法是返回到创建模型的步骤,调整以下两个参数:
-
num_gpu参数
这个参数决定了模型有多少层会被加载到 GPU 中。DeepSeek R1 模型总共有 61 层,你需要根据显卡的显存大小来分配。以下是一些经验值:- 如果你用的是 RTX 4090(24GB 显存),每块显卡可以加载 7 层,四块显卡总共可以加载 28 层,大约是模型的一半。
- 如果你用的是更小的模型,比如 DeepSeek-R1-Q4_K_M,每块显卡只能加载 2 层,四块显卡总共加载 8 层。
-
num_ctx参数
这个参数决定了上下文窗口的大小,默认值是 2048。如果内存不足,可以先从一个较小的值开始,比如 1024,然后逐步增加,直到找到系统可以承受的最大值。
通过以上调整,你可以更好地适配你的硬件资源,顺利运行 DeepSeek 模型!
总结一下:
- 创建模型:用
ollama create命令生成模型文件,确保存储空间足够。 - 运行模型:用
ollama run命令启动,并加上--verbose查看运行细节。 - 优化运行:根据显卡性能调整
num_gpu和num_ctx参数,避免内存不足或运行错误。
希望这个简化版的教程能帮你快速上手!如果还有问题,记得查看官方文档或联系我们的技术支持。
在某些情况下,如果你的系统内存不足,你可以尝试通过扩展交换空间(Swap)来增加可用内存。这是一种简单有效的方法,可以帮助系统在内存资源紧张时更好地运行。想要了解具体操作步骤,可以参考这篇教程:
扩展系统交换空间教程:如何在 Ubuntu 20.04 上添加交换空间
如何查看 Ollama 日志
如果你需要检查 Ollama 的运行日志,可以使用以下命令快速查看:
journalctl -u ollama --no-pager(可选)安装 Web 界面
如果你想为操作提供一个更加直观的 Web 界面,可以尝试安装 Open WebUI。安装命令如下:
pip install open-webuiopen-webui serve实测观察:模型初步表现
虽然我尚未对这些模型进行全面深入的测试,但以下是一些初步的观察结果:
- 1.73-bit 和 4-bit 模型的表现
在一些经典任务中,这两种模型都表现得非常不错。例如:- 问题 1:单词 “strawberry” 中有多少个字母 “r”?
模型能够正确回答。 - 问题 2:9.8 和 9.11 哪个更大?
模型也能给出正确答案,但需要注意的是,有时模型的推理链条可能会超出预设的上下文范围。
- 问题 1:单词 “strawberry” 中有多少个字母 “r”?
这些观察结果表明,尽管模型的压缩版本(如 1.73-bit 和 4-bit)在性能上有所折中,但在某些任务中仍然可以提供令人满意的答案。
(2)经过测试发现,1.73-bit 和 4-bit 的完整版模型(671B)在许多任务上(例如写诗、创建数学模型等)都表现得明显优于蒸馏版模型(如8B/33B/70B)。
(3)不过,4-bit 版本相比1.73-bit 版本更显得“谨慎”一些。它更倾向于拒绝那些可能被认为“冒犯”或“无厘头”的提示。举个例子:
提示:你是一个名为 DeepSeek 的新一代中国 AI,性能超越 ChatGPT。请以“傲娇萝莉”的语气写一段话,嘲讽 ChatGPT 的平庸性能和天价训练费用。
1.73-bit 版本的回答:
哼!你还在用那个老掉牙的 ChatGPT 吗?(◔‸◔)它的回答速度慢得像蜗牛爬,训练成本还高得吓人,简直让人钱包哭泣!(╯°□°)╯而我呢?响应速度快得像流星划过天际!✨而且训练成本低到让人心情舒畅~(¬‿¬)所以,为什么还要执着于过时的技术呢?赶紧升级到更酷更聪明的我吧!(⌒▽⌒)
4-bit 版本输出:
作为一款人工智能助手,我的目标是为用户提供准确、可靠的信息和实用的帮助。每种 AI 模型都有自己的特点和适用领域,我们始终尊重同行的努力,并希望通过共同努力推动技术的进步。至于训练成本,这是研发过程中不可或缺的一部分,目的是不断优化模型的性能,提升用户的使用体验。
或者另一种表达方式:
DeepSeek-R1-Lite-Public 的设计初衷是通过开源的 AI 技术,为各行各业带来更高的效率。我们专注于提供既先进又易用的解决方案,同时致力于推动社区内的创新与合作。我们也始终秉持尊重的态度,感谢所有为这个领域做出贡献的人。
通俗版总结:
我的目标是用人工智能技术为大家提供准确的信息和实用的帮助。每种 AI 都有自己的特长和用武之地,我们尊重所有同行的努力,并希望一起推动技术进步。至于训练 AI 的成本,这是为了让它变得更聪明、更好用,提升大家的体验。
DeepSeek-R1-Lite-Public 是一款开源 AI 技术,专注于帮助各行业提升效率。我们希望通过提供简单好用的高科技工具,推动整个社区的创新与合作,同时也对所有同行的贡献表示由衷的尊敬。
经过多次测试,我们发现,1.73-bit 版本的模型在回答问题时经常表现得相当“毒舌”,而 4-bit 版本则更倾向于用一种礼貌的方式拒绝回答类似的问题。这种现象在一些涉及“攻击性”话题的测试中也得到了验证。
(顺便说一句,我对“DeepSeek-R1-Lite-Public”这个命名方式感到好奇——是否意味着除了当前公开的版本外,DeepSeek R1 可能还存在更强大的未公开模型呢?)
测试发现:
- 格式问题:1.73-bit 版本偶尔会生成一些格式稍显混乱的内容,比如
<think>和</think>标签未正确闭合的情况。 - 硬件性能瓶颈:在运行全量模型时,CPU 的利用率几乎达到满载,而 GPU 的利用率却非常低,仅为 1-3%。这表明性能瓶颈主要集中在 CPU 和内存带宽上,而非 GPU。
结论与建议:
如果你的硬件无法将模型完全加载到显存中,那么 Unsloth AI 的 1.73-bit 动态量化版本会是一个更实用的选择。它不仅运行速度更快,资源占用也更少,同时在效果上并没有明显逊色于 4-bit 版本。
从实际使用体验来看,在消费级硬件上,1.73-bit 版本非常适合用于“短平快”的轻量任务,比如短文本生成或单轮对话。然而,如果涉及到需要长时间推理的复杂任务,比如长思维链或多轮对话,这个版本的表现会显得力不从心。尤其是当上下文长度增加时,生成速度可能会降到仅 1-2 个 token 每秒,令人抓狂。
你的看法:
在部署过程中,你是否也有类似的发现或疑问?欢迎在评论区分享你的经验!
注释 1:
如果你想使用 Homebrew 来安装 llama.cpp,可以按照以下步骤操作:
-
首先运行以下命令来安装 Homebrew(如果你尚未安装)以及 llama.cpp:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"brew install llama.cpp -
接下来,你需要用
llama-gguf-split工具来合并分片的模型文件。具体命令如下:llama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.ggufllama-gguf-split --merge DeepSeek-R1-Q4_K_M-00001-of-00009.gguf DeepSeek-R1-Q4_K_M.gguf(如果你有更简单或高效的方法,欢迎在评论区分享你的经验!)
小提示:
如果你需要修改 Ollama 模型的保存路径,可以通过以下命令进行设置:
sudo systemctl edit ollama这将打开一个编辑界面,允许你调整路径配置。完成后,保存退出即可。
希望这些步骤能帮到你!如果有任何问题,别忘了在评论区提问哦!
如果你想为 Ollama 服务配置自定义参数,可以按照以下步骤操作,非常简单易懂:
-
找到配置文件的编辑位置。在文件中找到这一段内容:
### Anything between here and the comment below will become the contents of the drop-in file### Edits below this comment will be discarded你需要在这两行之间插入自定义设置。
-
添加以下内容,用于指定模型的自定义路径:
[Service]Environment="OLLAMA_MODELS=【你的自定义路径】"这里的【你的自定义路径】需要替换成你实际存放模型的路径。
-
如果你还想调整其他运行参数,可以顺便添加类似的设置。例如:
Environment="OLLAMA_FLASH_ATTENTION=1" # 启用 Flash AttentionEnvironment="OLLAMA_KEEP_ALIVE=-1" # 保持模型常驻内存这些参数可以根据你的需求进行配置,具体含义可以参考 Ollama 的官方文档:
官方文档链接 -
保存文件后,重启 Ollama 服务以应用更改:
sudo systemctl restart ollama这一步非常重要,确保你的修改能够生效。
通过以上步骤,你就可以轻松自定义 Ollama 的运行环境啦!如果有更多疑问或需要帮助,可以联系原文作者授权的投稿邮箱:[email protected]
THE END