国产大模型DeepSeek-V3一夜火爆全球,671B的MoE,训练成本仅558万美元
今天,一款国产大模型在全球引起了轰动。
打开 X 社交平台,几乎全是关于 DeepSeek-V3 的讨论。这个模型有着惊人的 671B 亿个参数,而它的预训练过程只用了 266.4 万小时的 H800 GPU 计算资源,再加上后续的上下文扩展和后训练,总共也只用了 278.8 万小时。相比之下,Llama 3 系列的计算预算高达 3930 万小时的 H100 GPU 资源——这意味着用同样的资源可以把 DeepSeek-V3 训练至少 15 次。
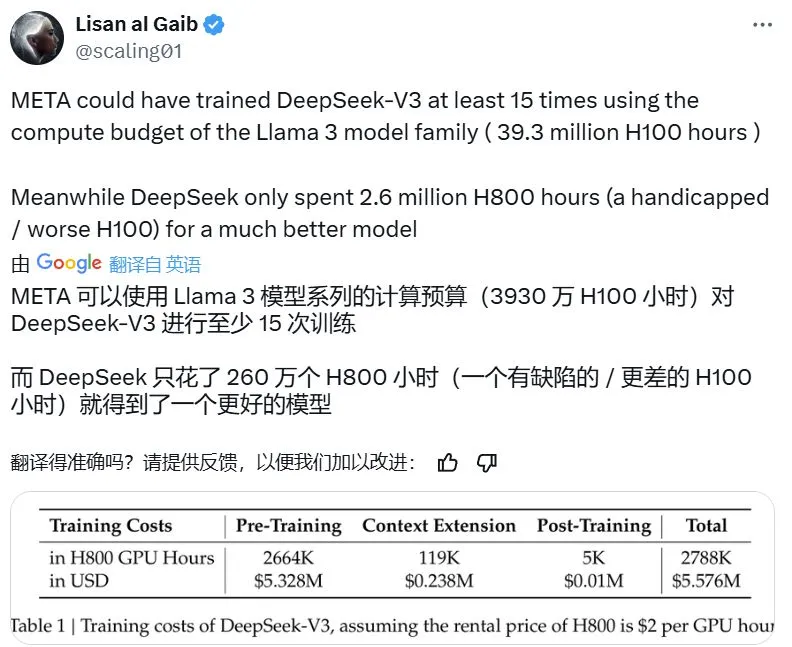
尽管 DeepSeek-V3 在训练时消耗的计算量比其他前沿大模型少,但它的性能却丝毫不逊色,甚至更胜一筹。
根据最新发布的 DeepSeek-V3 技术报告,这个基础模型在英语、编程、数学、汉语以及多语言任务上表现非常出色。在一些任务上,比如 AGIEval、CMath、MMMLU-non-English,它甚至远远超过了其他开源大模型。即便与 GPT-4o 和 Claude 3.5 Sonnet 这两大领先的闭源模型相比,DeepSeek-V3 也毫不示弱,尤其在 MATH 500、AIME 2024、Codeforces 等测试中表现出明显优势。
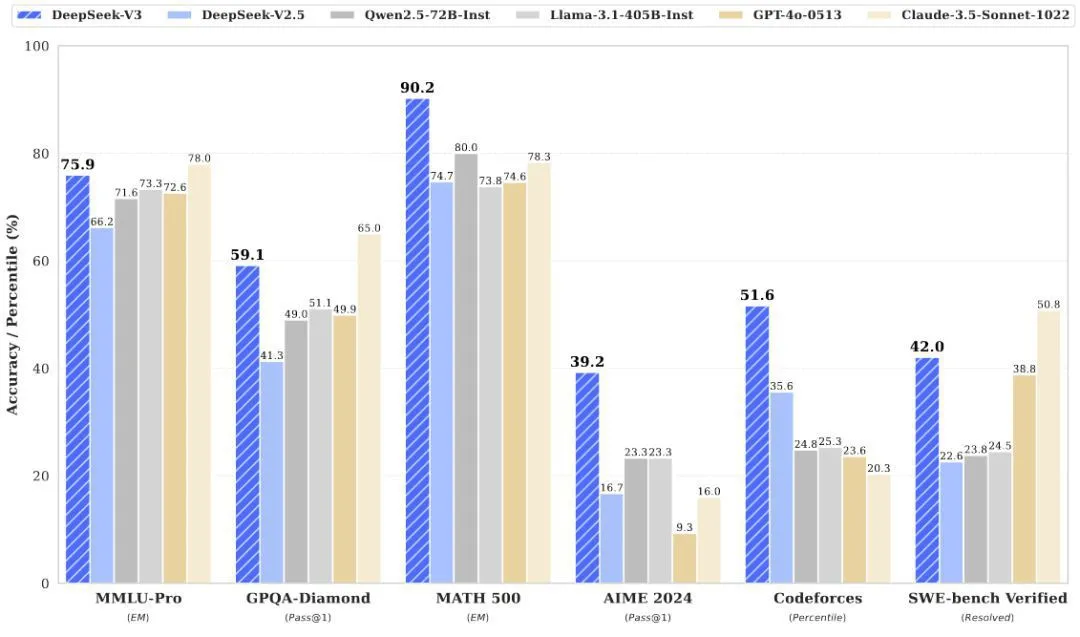
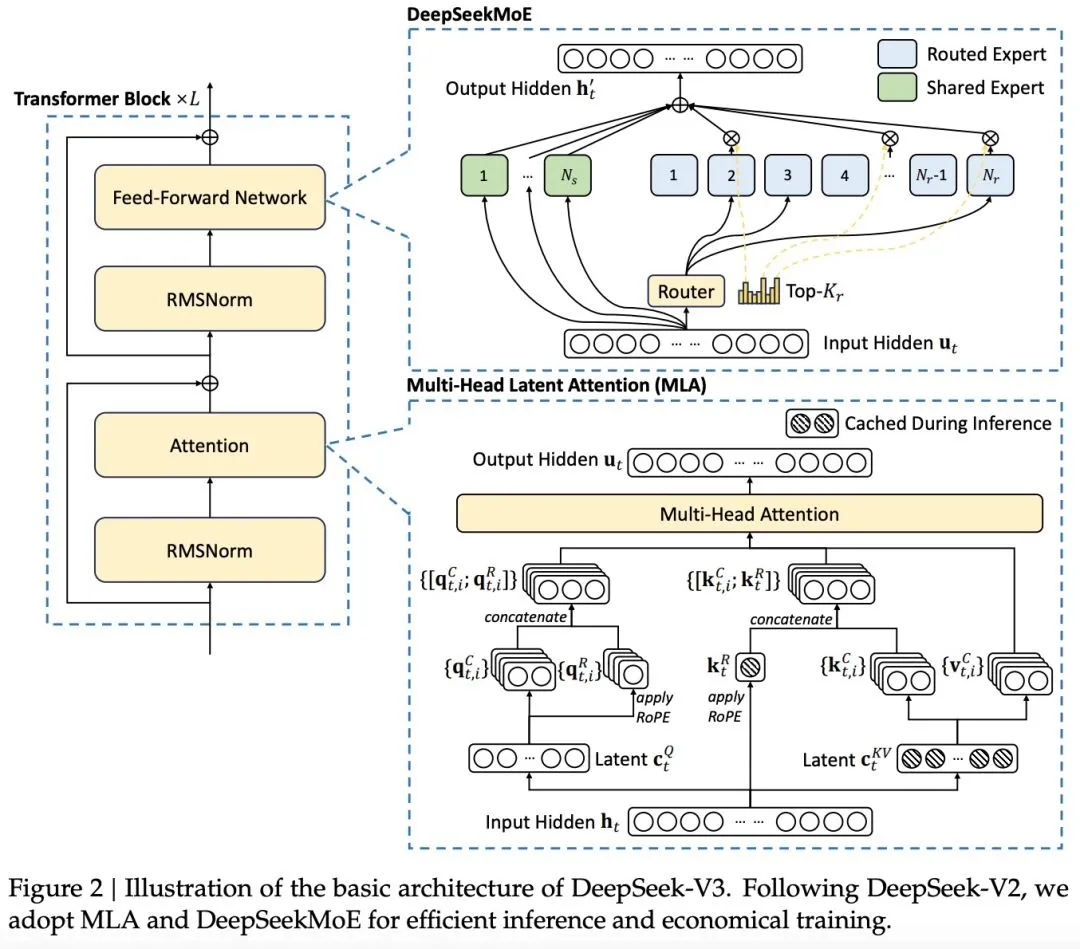
DeepSeek-V3 之所以表现出色,主要得益于它采用了 MLA(多头隐注意力)和 DeepSeekMoE 架构。这些技术在之前的 DeepSeek-V2 中已经被证明是有效的,现在也成为了 DeepSeek-V3 实现高效推理和经济训练的核心。
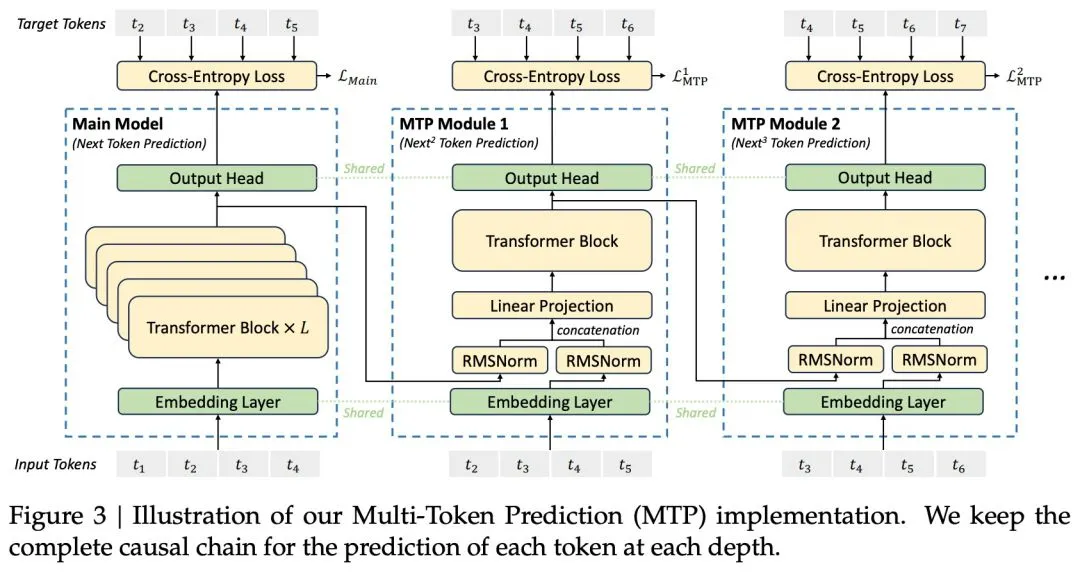
除此之外,DeepSeek-V3 首次引入了无辅助损失的负载平衡策略,并设定了同时预测多个 token 的训练目标,以提升其性能。他们在预训练中使用了 14.8 万亿个 token,然后进行了监督式微调和强化学习。
正是这些技术上的创新,使得开源的 DeepSeek-V3 一发布就获得了广泛好评。

Meta AI 的研究科学家田渊栋对 DeepSeek-V3 在各个方面的进展给予了高度评价。
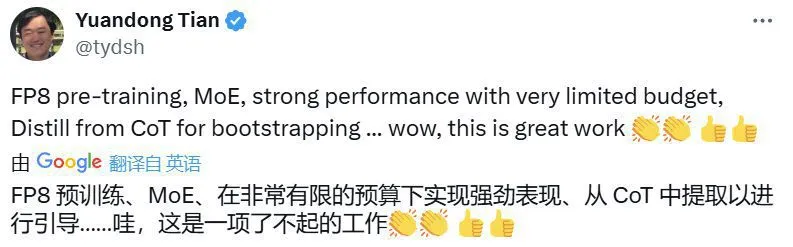
知名 AI 科学家 Andrej Karpathy 也表示,如果这个模型的优异表现能够被广泛验证,那么这将是资源有限条件下研究和工程的一次杰出展示。

正在创业的著名研究者贾扬清(Lepton AI)也发表了自己的深刻见解。他认为,DeepSeek-V3 的出现标志着我们正式进入了分布式推理的时代,因为其 671B 的参数量已经无法装入单台 GPU 中。

DeepSeek-V3 再次点燃了人们对开源模型的热情。根据 OpenRouter 的数据,自从昨天发布以来,DeepSeek-V3 在该平台上的使用量已经增长了三倍!

一些已经尝试过 DeepSeek-V3 的用户已经开始在网上分享他们的使用体验。
接下来,我们来看看技术报告的内容。

- 报告链接:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek\_V3.pdf
- 项目链接:https://github.com/deepseek-ai/DeepSeek-V3
- Hugging Face 页面:https://huggingface.co/collections/deepseek-ai/deepseek-v3-676bc4546fb4876383c4208b
架构
为了让推理更快、训练更省钱,DeepSeek-V3 使用了一种叫多头潜在注意力(MLA)的技术(DeepSeek-AI,2024c),这能让推理更高效。为了让训练更经济,它还采用了 DeepSeekMoE(Dai et al., 2024)。此外,DeepSeek-V3 引入了一种新的训练目标,叫做多 token 预测(MTP),这能提升整体性能。在其他方面,DeepSeek-V3 基本上沿用了 DeepSeek-V2(DeepSeek-AI,2024c)的设置。
与 DeepSeek-V2 不同的是,DeepSeek-V3 额外引入了一种辅助无损耗负载平衡策略(Wang et al., 2024a),用于 DeepSeekMoE。这种策略的目的是避免因为负载平衡而导致性能下降。图 2 展示了 DeepSeek-V3 的基本结构:
预训练
MTP 训练目标的作用是让模型在每个位置上预测多个未来的 token。这样做有两个好处:一方面,它让训练信号更密集,提高了数据使用效率;另一方面,它帮助模型更好地规划和预测未来的 token。
数据构建
与之前的 DeepSeek-V2 相比,DeepSeek-V3 通过增加数学和编程样本的比例来改进其预训练的数据集,并且不仅限于英语和中文,还扩展到了更多的语言。此外,新版本优化了数据处理流程,以减少重复内容,同时保持数据集的多样性。DeepSeek-V3 的训练数据集中包含了 14.8 万亿个高质量且多样化的 token。
模型参数设置
在模型参数方面,我们将 Transformer 的层数设定为 61,隐藏层的维度为 7168。所有可学习的参数都以标准差 0.006 进行随机初始化。在多头注意力机制(MLA)中,注意力头的数量设定为 128,每个头的维度为 128。
另外,除了前三层之外,我们用 MoE(专家混合)层替换了所有的 FFN(前馈神经网络)层。每个 MoE 层由一个共享专家和 256 个路由专家组成,每个专家的中间隐藏层维度为 2048。在路由专家中,每个 token 会激活 8 个专家,并且每个 token 最多会被发送到 4 个节点。
与 DeepSeek-V2 一样,DeepSeek-V3 在压缩潜在向量后使用了额外的 RMNSNorm 层,并在宽度瓶颈处应用了额外的缩放因子。在这种配置下,DeepSeek-V3 总共包含 6710 亿个参数,其中每个 token 激活 370 亿个参数。
长上下文扩展
本文采用了一种类似于 DeepSeek-V2 的方法,在 DeepSeek-V3 中引入了长上下文处理功能。经过初步训练后,我们使用 YaRN 技术来扩展上下文范围,并进行了两个额外的训练阶段。每个阶段包含 1000 个步骤,逐步将上下文窗口从 4K 扩展到 32K,再扩展到 128K。
通过这种分阶段的扩展训练,DeepSeek-V3 能够处理长达 128K 的输入数据,同时保持出色的性能。图 8 显示了在经过监督微调后,DeepSeek-V3 在“大海捞针”(NIAH)测试中表现优异,即使在长达 128K 的上下文窗口中也能保持一致的稳定性。

评估
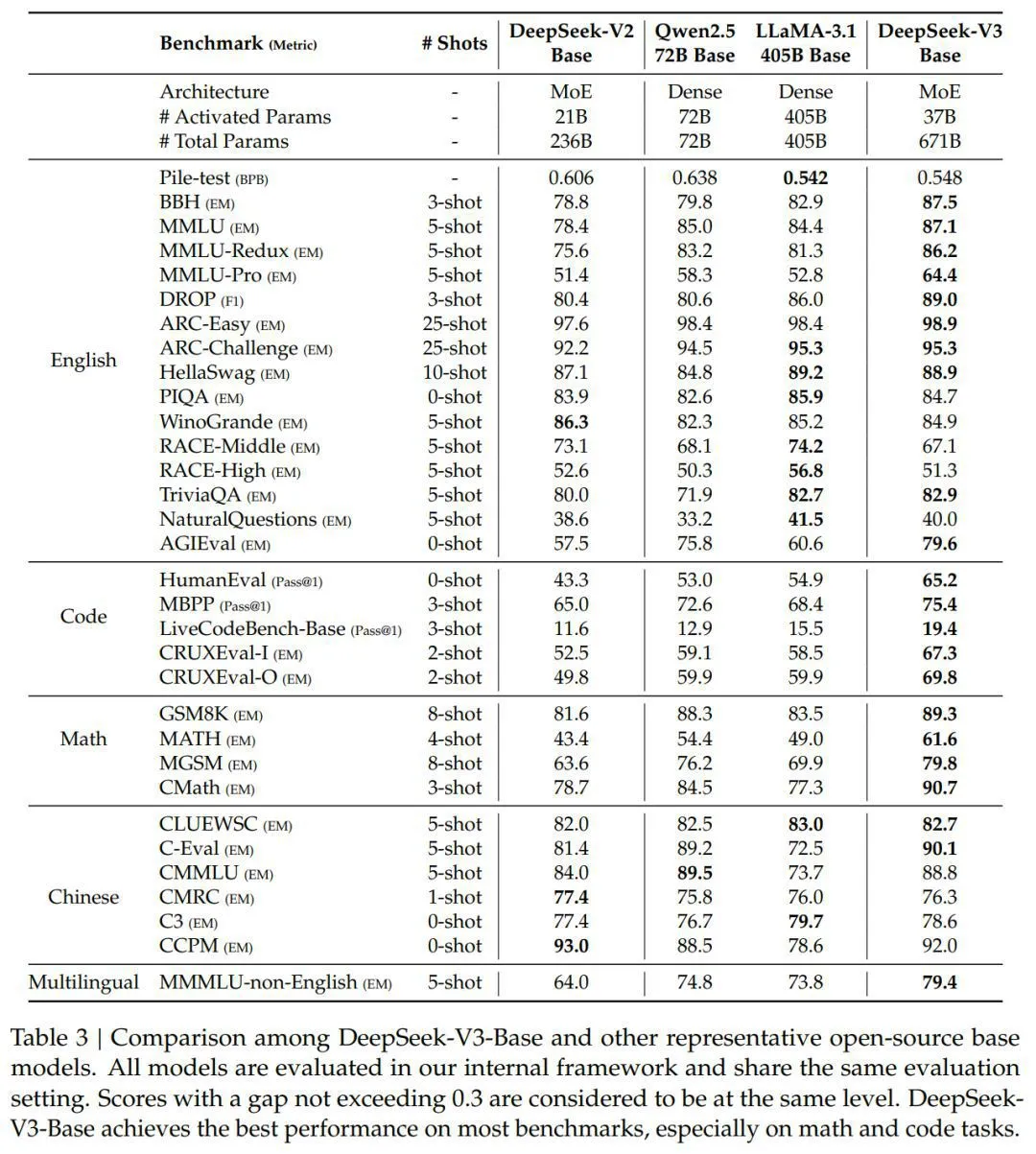
表 3 对比了 DeepSeek-V3 的基础模型与其他顶尖性能的开源基础模型,包括 DeepSeek-V2-Base、Qwen2.5 72B Base 和 LLaMA-3.1 405B Base。总体来看,DeepSeek-V3-Base 在各方面都超越了 DeepSeek-V2-Base 和 Qwen2.5 72B Base,并在大多数测试中超过了 LLaMA-3.1 405B Base,几乎成为最强的开源模型。
具体来说,本文分别将 DeepSeek-V3-Base 与其他开源基础模型进行了详细比较。
(1)DeepSeek-V3-Base 通过改进模型结构、增加模型大小和训练数据量,以及提高数据质量,相较于 DeepSeek-V2-Base,表现得更为出色,达到了预期的效果。
(2)即便 DeepSeek-V3-Base 的激活参数只有当前最先进的中文开源模型 Qwen2.5 72B Base 的一半,它在许多方面仍然表现得更好。特别是在英文、多语言、代码和数学的测试中,DeepSeek-V3-Base 展现了明显的优势。对于中文测试,除了中文多学科多项选择题 CMMLU 之外,DeepSeek-V3-Base 也优于 Qwen2.5 72B。
(3)即使与目前最大的开源模型 LLaMA-3.1 405B Base(其激活参数量是 DeepSeek-V3-Base 的 11 倍)相比,DeepSeek-V3-Base 在多语言、代码和数学测试中也表现得更佳。在英语和中文的测试中,DeepSeek-V3-Base 的表现与 LLaMA-3.1 405B Base 相当或更好,尤其是在 BBH、MMLU 系列、DROP、C-Eval、CMMLU 和 CCPM 上表现优异。
由于其高效的架构和全面的工程优化,DeepSeekV3 的训练效率极高。基于其训练框架和基础设施,在 V3 上训练每万亿个 token 仅需 180K H800 GPU 小时,这比训练 72B 或 405B 大型模型要便宜得多。
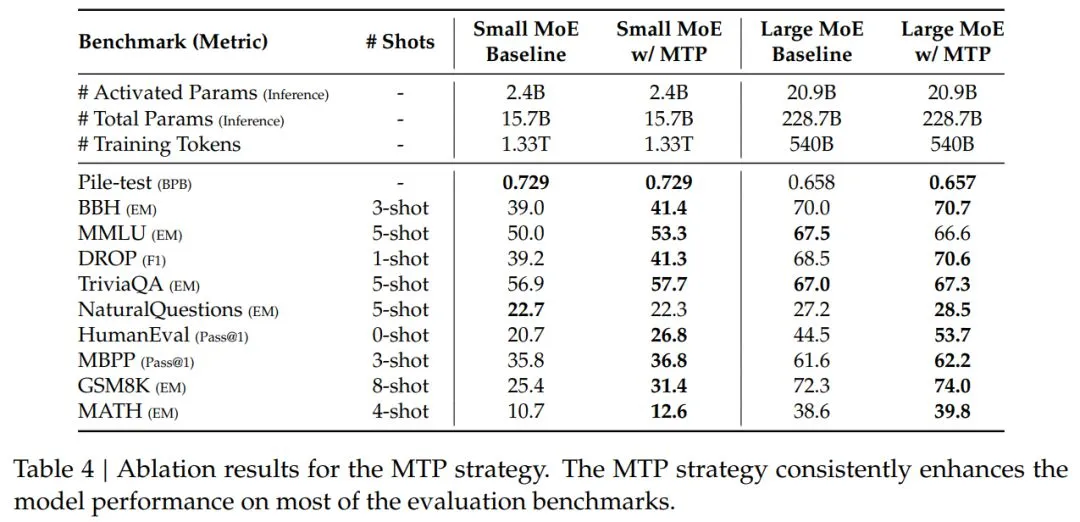
表 4 展示了 MTP 策略的测试结果,研究人员在两种不同大小的基线模型上测试了这个策略。通过表格,我们可以看到,MTP 策略在大多数测试标准上都提升了模型的表现。
接下来的文章中,研究人员还介绍了后期训练的细节,包括监督微调和强化学习等内容。
想要了解更多,请查看原始论文。